嵌入式 Linux 与并不前沿的前沿技术
实在想不出标题了,这次就原谅我吧。
暑假多接触了些嵌入式设备,加上 AOSCC 2023 上各路神仙带来的机器,已经可以说是让我大开眼界了。半年前确实完全想不到自己还会重新去碰这鬼东西……
我手里能用嵌入式 Linux 的嵌入式设备多半还是些有一定计算属性、和单片机开发板比更接近一般 PC 的机器。C51 或者 STM32 之类偏工业控制的东西我是完全玩不懂的。
本来打算九月之前写完上传的,结果开学后就忙得要命。恍惚之间,仿佛看到……算了,这个引用再拿来用就无聊了。总之很难抽出时间深入了解下这些硬件。
硬件
Raspberry Pi 4B
树莓派的知名度之高,在嵌入式领域之外也能看出来。RPi 4B 搭载 BCM2711,28nm,稍稍超个频就很烫。手上的设备是学校实验室财产,所以也不好给它原有的散热器拆掉粘个新的上去,就稍微改了下原有的可拆卸的散热器,下面会具体讲。
这家伙 CPU 性能一般般,GPU 性能很弱,带起 Minecraft 来比较艰难,各方面硬件都给不了人惊喜。好在树莓派基金会比较重视社区建设,资料也好找,用起来不折腾,新的 Raspberry Pi OS 12 在驱动上提升也比较明显。话说 RPi 还有 EFI 固件,不过我还没试。
我在树莓派上用的是 Raspberry Pi OS,主要还是因为其他发行版表现不是特别好。
X96 Max Plus V5.1
一台电视盒子,价值在于能运行第三方 Armbian 之类的发行版。
二百块钱的设备能有主线内核和爆杀树莓派的 CPU 性能,还带 NPU(虽然我不会用),说实话已经很难得了。缺点是文档几乎没有,做工比树莓派差(这当然并不是在说树莓派的做工好),网卡之类外围设备有时候会出问题。它的原厂系统特别难用,单纯当电视盒子的话我肯定不愿意花二百块钱买它。
盒子搭载 12nm 的 AmLogic s905x3,CPU 有负载也比较凉快,用 GPU 就比较容易过热了。最好把原厂的散热拆掉,换个好的上去。
s905x3 CPU 性能几乎是 RPi 4B 的两倍,GPU 也强一点(不过似乎在新驱动上被 RPi 4B 压下去了),运行 KDE 会明显比 RPi 4B 顺滑,可惜图形有概率出现和我 PinePhone 一样不稳定的情况,不知道是不是 Mali 系列 GPU 的通病。
电视盒子同一型号常有不同版本,安装系统要麻烦得多,我建议你直接把壳子打开(反正也别苛求能在大陆享受外贸盒子的售后),对着主板上的丝印和芯片型号找找有没有人适配第三方 Armbian。有的话,下载系统镜像,写入存储盘。这时候先别插盘上电,先在电脑上挂载存储盘,按照说明设定正确的 DTB,选择合适的 U-boot,之后再把存储盘插盒子上,按住盒子里隐藏的、允许盒子从外接存储盘启动的按钮,插电。以后启动就不需要再按那个隐藏的按钮了。
这机器默认从 eMMC 启动,所以如果把 eMMC 上的引导程序搞坏了,就算有制作好的启动盘也没法正常启动。我嫌 U 盘慢就把系统覆盖到 eMMC 上,砖了。我手上这台从 SD 卡启动就总是会有问题,eMMC 与 SD 同源,所以系统在 eMMC 上不正常也说得通。引导程序坏了,要用镊子短接主板上的一对触点,用一根 USB-A 公对公线从盒子的 USB 3.0 口连接电脑,用 AmLogic 提供的工具来恢复。
我的盒子 eMMC 上装了 SlimBox,第三方 Armbian 就用 U 盘来启动了。我用的 Armbian 默认给 CPU 频率超到了 2.2 GHZ。
Visionfive 2
现在确实不是入手 RISC-V 的好时候。Visionfive 2 用了一颗 JH7110,不支持 RVV (RISC-V Vector Extension),不支持硬件虚拟化,没有 NPU。制程我没查到,主观感觉芯片比 RPi 4B 的凉一点。
RVV 和 x86/ARM 上 SIMD 实际解决的问题差不多,没 RVV 就有点类似于用没 AVX (或者极端点,SSE MMX 都没有)的 x86电脑,基本要和多媒体、游戏、科学计算 say goodbye~ 了;硬件虚拟化暂时不算刚需,不过没有它的确是少了很多乐趣。
我刚开完箱就被 Revy 全身上下吐槽了一遍,这才知道 LicheePi 4A 的 TH1520 性价比要高得多,支持 RV 0.7.1,还带 NPU,不过我想等同时有 RVV 1.0 以上和硬件虚拟化的芯片多起来再买新机器。
当然 Visionfive 2 当实验材料以及拿来展示的效果应该说得过去,不至于吃灰,只是七百多块的实验材料的确太贵了。
JH7110 的 PowerVR GPU 动画很顺滑,不过 Visionfive 2 的 HDMI 兼容性大约不太好,我用 HDMI-DVI 转换器和 HDMI 采集卡都没反应,插 HDMI-VGA 转换器上才亮起来。
Visionfive 2 官方提供的系统是 Debian Sid,其中他们主要改动的是 Mesa……总之很不稳定就是了。
Milk-V Duo
这玩意在这几个里算比较特殊,它是块核心板,有点像树莓派 Pico,拿出去别人可能会以为是 STM32 那种单片机。
拿到 Duo 当然也是一分钱没花(笑),社团的五块里还有两块都没拆封。Duo 主板上只有一颗芯片(CV1800B,它的 SoC),大概是把内存之类的也集成在一起了。芯片是 7mm*7mm,和常见的 8 脚 SPI 闪存差不多大,完全没法装散热器,不过机器功耗足够低,所以没关系。
Duo 的一个核心是 1GHz,另一个是 700MHz,Linux 下低频的那个核心好像用不了。文档说低频的那颗只能用来跑 RTOS,又说 Linux 和 RTOS 可以同时运行,我不知道是什么原理。我离了 Linux 就什么也不会,就把它当单核来用了。这核心有 RVV 0.7.1,这下更显得花七百多块买 Visionfive 2 的我是在自取其辱了。Duo 还有个 TPU(不知道和 s905x3 上的 NPU 有什么区别),我一样不会用。
Duo 有 64M 内存(不错,比我那台 armv4l 强),默认系统镜像里要留一半内存给多媒体处理,如果不需要相关功能的话,可以改 Duo Buildroot SDK 里的参数把这部分内存要回去。这么小的内存也没什么运行带包管理器的主流发行版的可能,装软件就从 Buildroot 里选吧,自己编译也行。入门要先学会 Buildroot,这个确实让它显得比别的开发板更难上手,再加上文档的各种问题……有厂商会给我那末流本科供应开发板也就说得通了。
散热
学校的 RPi 4B 和我的 Visionfive 2 都有配主动散热器:一个风扇,对着金属鳍片吹。这种散热器本身应该能轻松压住开发板的发热,但散热器是用一片导热硅胶和 SoC 贴在一起的,这样压力全在导热性能上了。我以为会有人给这些开发板设计带弹簧、直接涂硅脂来用的散热器,哪知没有,只能自己解决导热问题了。
要是直接把厚厚一片导热硅胶换成涂上硅脂的金属片,搞不好散热器的弹力会把开发板压坏。我买了一组不同厚度的铜片,选择厚度略小于散热器与 SoC 间距的一片,在散热器上涂上导热硅胶,SoC 上涂硅脂,之后压在一起。导热硅胶黏度比较高,刚涂上时会顶着铜片凸出来,让硅脂-铜片-导热硅胶的厚度略大于散热器与 SoC 的间距,之后导热硅胶一层受压变扁,就能保证散热器与 SoC 间刚好被导热硅胶和硅脂紧密填充了。

这是用导热硅胶粘在散热器上的铜片。因为一开始涂得有点多,所以刮掉了一点,免得多余的部分被挤出来粘到 SoC 上拿不掉。

涂上硅脂压实后稍微抬起一点,大概就是这样。
控制设备
RPi 4B、X96 Max Plus 和 Visionfive 2 这样带 HDMI、USB 口的设备可以直接插键盘鼠标显示器操作。如果需要高速连接,我有时候也直接用以太网线连接开发板:NetworkManager 有个一键在笔记本上启动个 DHCP 服务器,把笔记本当成路由器的功能,比手动设置 DHCP 方便了不少。这个功能在修电脑的时候也很好用,只是有时候会不停断线重连,不知道是硬件还是软件有问题。
Milk-V Duo 就不能直接插显示器了,官方推荐的做法是直接用 USB 线连接电脑,开发板默认会通过 usb_gadget 的 RNDIS 功能把自己模拟成一张网卡,这样就能在电脑上 ssh 登录开发板了。openSUSE Leap 15.5 某次更新之后默认不加载 rndis_host 模块了(改之前也不和我说一声,我还以为开发板坏了),应该和 Linux 移除 RNDIS 的计划有关,用的时候手动加载一下模块就好了。
当然这里除了 X96 Max Plus 外,连接 UART 也都比较容易,只是我平时不想拖这么多硬件。连接 UART 时我用的是 PuTTY。
系统引导
我并不是很懂计算机的底层原理,只能按照对 x86 系统的认知稍微理解一下这几块开发板的引导过程。我手里的开发板都可以用 U-boot,系统启动的时候由某种更底层的程序加载 U-boot,之后 U-boot 搜索存储盘,找到、加载 Linux,完成启动;U-boot 还能当 EFI 固件来着,所以 U-boot 至少同时有我的 x86 电脑上 UEFI BIOS、GRUB(x86) 两层引导程序的地位。
话说 RPi 4 上 openSUSE 是由 U-boot 加载 GRUB,GRUB 再加载 Linux 来引导的,感觉很是神奇。
Buildroot 和主流发行版都给引导程序的配置封装好了,一般情况下不用太关心引导问题,我也就不班门弄斧了。
GPU 的 3D 加速与通用计算
我并不打算日常用这些开发板打游戏,所以还是更关心通用计算的能力,至于 3D 加速的部分简单用 glmark2 测试下就是了。
RPi 4B、X96 Max Plus 和 Visionfive 2 理论上都能支持 Vulkan Compute,理论上能搞 GPGPU,实际效果就说不定了。关于对性能要求高的通用计算,我对机器学习的理解程度只达到了能看懂儿童科普读物的水平,其他领域也一概不会,只能跑跑基准测试。腾讯有个叫 NCNN 的机器学习框架,对 SIMD、RVV 和 Vulkan Compute 的支持都有,就拿它自带的工具来测试好了。
RPi 4B
RPi 4B 在 Raspberry Pi OS 12 上的 vc4/v3d 驱动表现不错,图形 API 原先支持的版本不高,现在已经能检测到 OpenGL 3.1/GLES 3.1/Vulkan 1.3 了,可惜它 GPU 性能太低,上 Vulkan Compute 还要比 CPU 慢得多……关于 Vulkan 渲染,我试着用 Zink 运行下 glmark2,画面是卡住的;vkcube 倒是能正常显示。不加载 Zink,glmark2(Wayland)有 780 分。
vc4/v3d 用户空间驱动是开源的,但用 openSUSE 启动就没法正常硬件加速,在 Raspberry Pi OS 上启动 openSUSE 容器(把 /dev/dri 通进容器)却没问题,不知道是 openSUSE 没配好,还是原厂系统上存在一些闭源的内核驱动。
关于内核驱动和用户空间驱动,感兴趣的同学去看看 Linux DRI 就是了……反正我也完全不懂,只是外界的评价(见第 53 页)似乎并不是很高。用 N 卡的时候能在宿主机上只装开源内核驱动,而在容器里装闭源用户空间驱动的话确实要方便一点,但是装个 Flatpak 要同时装两个显卡驱动、用 VirGL 图形性能会受内核-用户态间多次转换而打骨折的问题也十分棘手……跑题了。
Vulkan Compute 当然就用 NCNN 测了,同时也测下用 CPU 运算的性能。我编译 NCNN 的时候给 CMake 加了 -DCMAKE_BUILD_TYPE=Release。NCNN 基准测试用的模型参数在源代码路径下,要在这个路径下 benchncnn 程序才能找到参数文件……benchncnn 输出的结果是时间,所以越小越好。
测试完发现 Vulkan Compute 真变成硬件减速了……
| Model | Vulkan | CPU | Ratio |
|---|---|---|---|
| squeezenet | 298.37 | 46.76 | 15.67% |
| squeezenet_int8 | 43.36 | 40.27 | 92.87% |
| mobilenet | 371.72 | 63.96 | 17.21% |
| mobilenet_int8 | 37.41 | 35.29 | 94.33% |
| mobilenet_v2 | 273.21 | 61.78 | 22.61% |
| mobilenet_v3 | 266.29 | 46.65 | 17.52% |
| shufflenet | 171.36 | 33.83 | 19.74% |
| shufflenet_v2 | 226.22 | 24.15 | 10.68% |
| mnasnet | 274.26 | 51.98 | 18.95% |
| proxylessnasnet | 286.06 | 54.81 | 19.16% |
| efficientnet_b0 | 483.66 | 77.36 | 15.99% |
| efficientnetv2_b0 | 720.6 | 82.9 | 11.50% |
| regnety_400m | 343.93 | 73.59 | 21.40% |
| blazeface | 82.57 | 8.79 | 10.65% |
| googlenet | 794.13 | 126.45 | 15.92% |
| googlenet_int8 | 103.21 | 99.97 | 96.86% |
| resnet18 | 854.74 | 126.29 | 14.78% |
| resnet18_int8 | 81.53 | 75.65 | 92.79% |
| alexnet | 482.72 | 82.27 | 17.04% |
| vgg16 | 4529.85 | 571.87 | 12.62% |
| vgg16_int8 | 400.62 | 395.42 | 98.70% |
| resnet50 | 1961.75 | 280.65 | 14.31% |
| resnet50_int8 | 213.19 | 199.2 | 93.44% |
| squeezenet_ssd | 1136.81 | 129.67 | 11.41% |
| squeezenet_ssd_int8 | 106.2 | 97.81 | 92.10% |
| mobilenet_ssd | 915.37 | 126.24 | 13.79% |
| mobilenet_ssd_int8 | 75.44 | 73.2 | 97.03% |
| mobilenet_yolo | 1826.17 | 286.25 | 15.67% |
| mobilenetv2_yolov3 | 893.05 | 191.85 | 21.48% |
| yolov4-tiny | 1654.64 | 218.29 | 13.19% |
| nanodet_m | 523.85 | 71.37 | 13.62% |
| yolo-fastest-1.1 | 235.75 | 45.21 | 19.18% |
| yolo-fastestv2 | 209.61 | 36.18 | 17.26% |
| vision_transformer | 45802.37 | 2547.61 | 5.56% |
| FastestDet | 215.75 | 36.24 | 16.80% |
X96 Max Plus
s905x3 用的 Bifrost GPU 有 Panfrost OpenGL/GLES 开源驱动。如果 RPi 4B 用 Raspberry Pi OS 11 的话,s905x3 上的 OpenGL 版本要比 RPi 4B 上的高一些,性能也稍好;RPi 4B 换成 Raspberry Pi OS 12 ,s905x3 的 glmark2 分数竟然就被压下去了,不过主观上还是 s905x3 的视觉效果更顺滑一点。
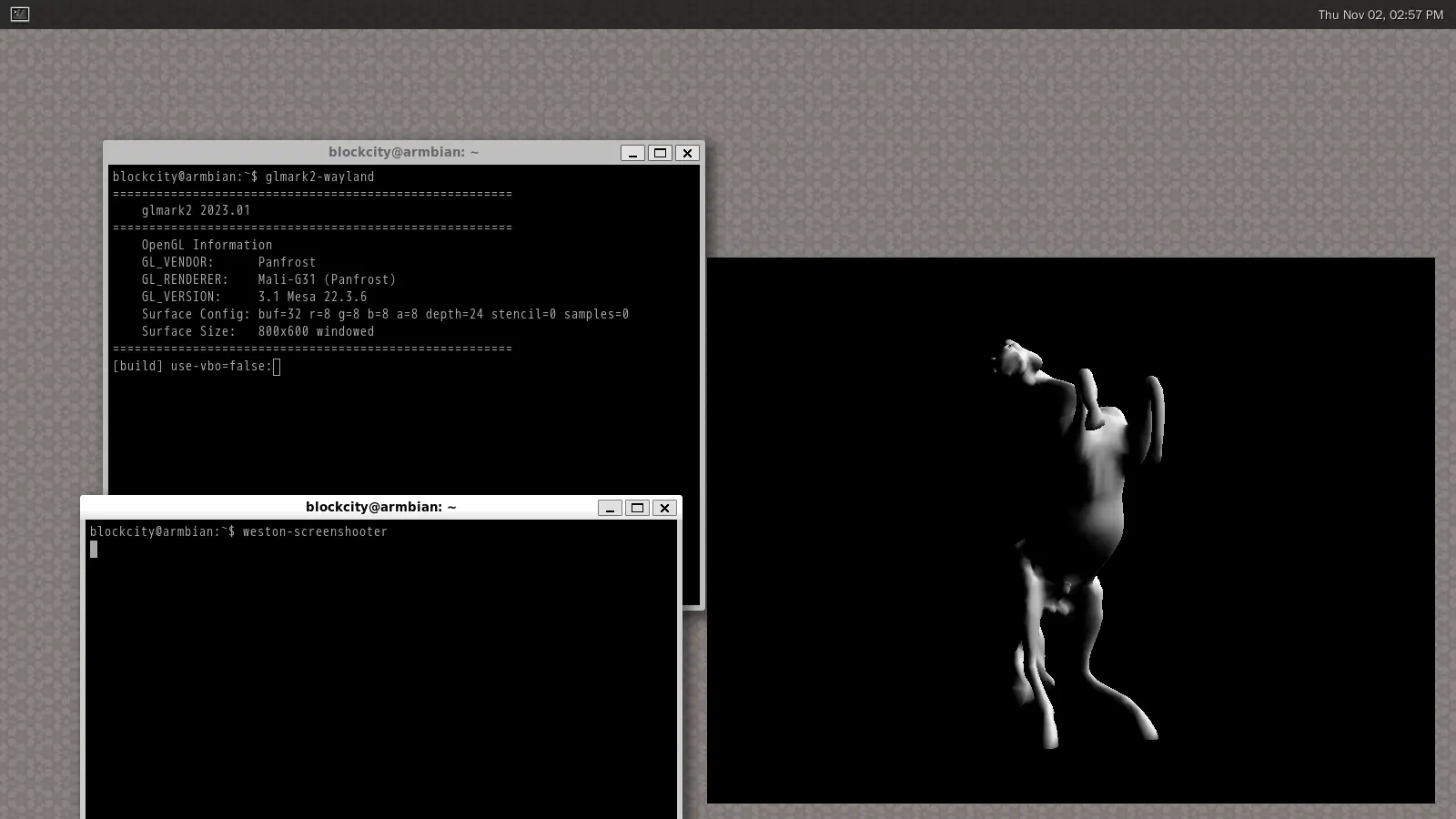
glmark2(Wayland)得了 526 分。截图是为了看视觉效果,我在实际跑分的时候没有乱动机器。
需要 Vulkan 就得用 PanVk,目前版本的 Armbian 没提供,要自己编译 Mesa。NCNN 主要作者也有关于这的教程。我在编译完设好 VK_ICD_FILENAMES 和 PAN_I_WANT_A_BROKEN_VULKAN_DRIVER 之后,编译 NCNN 之前还试了下 vulkaninfo 和 vkcube,结果 vkcube 说检测不到 VK_KHR_surface,显示不出画面;vulkaninfo 倒是能检测到 Vulkan 1.0 了。总之硬件加速支持比 RPi 4B 上差得多,不过 NCNN 对 Vulkan 的版本要求不高,所以也没大问题。
之后分别用 CPU 和 GPU(Vulkan Compute) 运行下 NCNN 基准测试,同样也是用 -DCMAKE_BUILD_TYPE=Release 编译,用 Vulkan Compute 的时候给 benchmark/benchmark.cpp 做了和教程里同样的改动;用 CPU 时没改。
之后发现用 Vulkan Compute 比 CPU 还慢的现象比在 RPi 4B 上还要明显……
| Model | Vulkan | CPU | Ratio |
|---|---|---|---|
| squeezenet | 294.09 | 20.79 | 7.07% |
| squeezenet_int8 | 28.21 | 20.45 | 72.49% |
| mobilenet | 286.56 | 26.93 | 9.40% |
| mobilenet_int8 | 33.79 | 23.47 | 69.46% |
| mobilenet_v2 | 199.89 | 27 | 13.51% |
| mobilenet_v3 | 471.68 | 21.55 | 4.57% |
| shufflenet | 161.8 | 17.56 | 10.85% |
| shufflenet_v2 | 143.47 | 14.66 | 10.22% |
| mnasnet | 201.17 | 23.24 | 11.55% |
| proxylessnasnet | 220.43 | 27.5 | 12.48% |
| efficientnet_b0 | 304.8 | 34.59 | 11.35% |
| efficientnetv2_b0 | 607.84 | 42.48 | 6.99% |
| regnety_400m | 257.59 | 35.87 | 13.93% |
| blazeface | 43.3 | 5.39 | 12.45% |
| googlenet | 1215.24 | 69.09 | 5.69% |
| googlenet_int8 | 79.82 | 66.21 | 82.95% |
| resnet18 | 1591.02 | 55.16 | 3.47% |
| resnet18_int8 | 52.33 | 47.55 | 90.87% |
| alexnet | 609.33 | 48.83 | 8.01% |
| vgg16 | 7785.7 | 303.21 | 3.89% |
| vgg16_int8 | 368.11 | 343.21 | 93.24% |
| resnet50 | 2744.06 | 124.75 | 4.55% |
| resnet50_int8 | 145.53 | 111.35 | 76.51% |
| squeezenet_ssd | 1163.9 | 67.84 | 5.83% |
| squeezenet_ssd_int8 | 74.34 | 64.68 | 87.01% |
| mobilenet_ssd | 603.74 | 62.19 | 10.30% |
| mobilenet_ssd_int8 | 59.77 | 49.38 | 82.62% |
| mobilenet_yolo | 1291.76 | 136.28 | 10.55% |
| mobilenetv2_yolov3 | 648.86 | 89.2 | 13.75% |
| yolov4-tiny | 2914.02 | 118.35 | 4.06% |
| nanodet_m | 313.59 | 43.58 | 13.90% |
| yolo-fastest-1.1 | 130.84 | 21.55 | 16.47% |
| yolo-fastestv2 | 119 | 18 | 15.13% |
| vision_transformer | 31808.15 | 2220.99 | 6.98% |
| FastestDet | 139.44 | 17.76 | 12.74% |
算了,我就当它没 Vulkan……
话说之前有群友先是好奇 PanVk 为什么没法正常渲染却能做 Vulkan Compute,随之又查了下 Khronos 官网,说意思大概是 Vulkan Compute 是 Vulkan 的一等公民吧。
Visionfive 2
Visionfive 2 上驱动显示是 pvr,应当是闭源驱动。总之图形性能很强,但是只给 GLES,也用不了 Vulkan。
缺 OpenGL 的问题本来可以用 gl4es 解决,但我的机器上 gl4es 总是 Segfault,明明社区的人和 gl4es 原作者都曾经在这开发板上正常跑起来过的。考虑到现在很难有时间持续跟进,就没去开 Issue……不知道等 Vulkan 支持后直接去用 Zink 会不会现实一点。
至于测试 NCNN……没意义,真的。
User-Mode Linux
没有的不存在的。现在没有这种适配。
QEMU
KVM
ARM 上运行 QEMU/KVM 并没有太复杂,只是各大发行版的文档太少,加上 QEMU 运行 ARM 虚拟机默认不给键盘鼠标显示器,初次上手会让人有点紧张,有种“人生地不熟”的刺激感。openSUSE 上有部分页面简单介绍了下系统在 ARM 上的用法,页面整体有点老,不过没关系。
RPi 4B 和 X96 Max Plus 都可以正常运行 QEMU/KVM 虚拟机。RISC-V 上……先前提过 Visionfive 2 不支持硬件虚拟化,我这边试不了。
安装 QEMU,qemu-system-aarch64 指定 -accel kvm,-machine 我直接选了 virt,-cpu 我总是 host,想开多核就 -smp cores=[数字](不含方括号)。想要键盘鼠标显示器就手动指明 -device qemu-xhci(没错默认连 USB 都不给)、-device usb-kbd、-device usb-tablet 和 -device virtio-gpu-pci。不用键盘鼠标显示器也没关系,系统启动之后直接用串行终端也行。
想要像 PC 一样能插安装盘、能用键盘调设置的体验,就用 -bios [位置] 加载个 UEFI 固件,这里是 TianoCore EDK 2。关于固件的位置,openSUSE 上在 /usr/share/qemu/aavmf-aarch64-code.bin,Debian 系上多在 /usr/share/qemu-efi-aarch64/QEMU_EFI.fd 下。
进 EDK 2,按 F12 就是很熟悉的界面:
想玩 U-boot 也可以自己编译一个,同样用 -bios [位置] 加载它。U-boot 默认要从串行终端进行调试,把 QEMU 视图切换到 serial0 就可以控制它了。
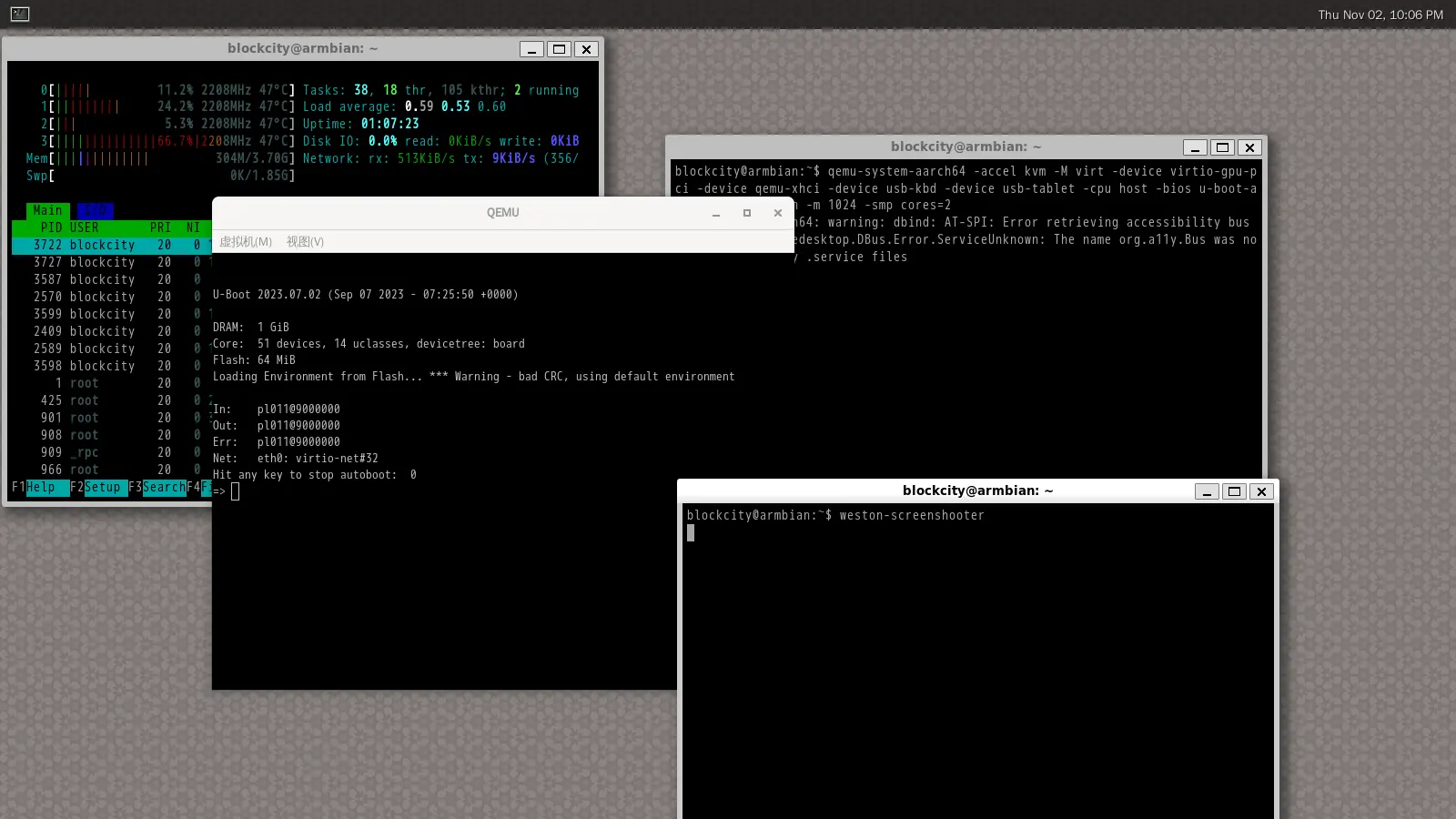
如果想在虚拟机里装的发行版提供了 ARM UEFI 镜像,那么直接用 -cdrom [位置] 加载安装盘就好了。虚拟硬盘往往可以直接用 VirtIO,具体取决于你要装的发行版支持情况。U-boot 和 EDK 2 都可以启动 UEFI 启动镜像……相较于同 Device Tree 斗智斗勇,用 UEFI+ACPI 确实要轻松愉快得多。
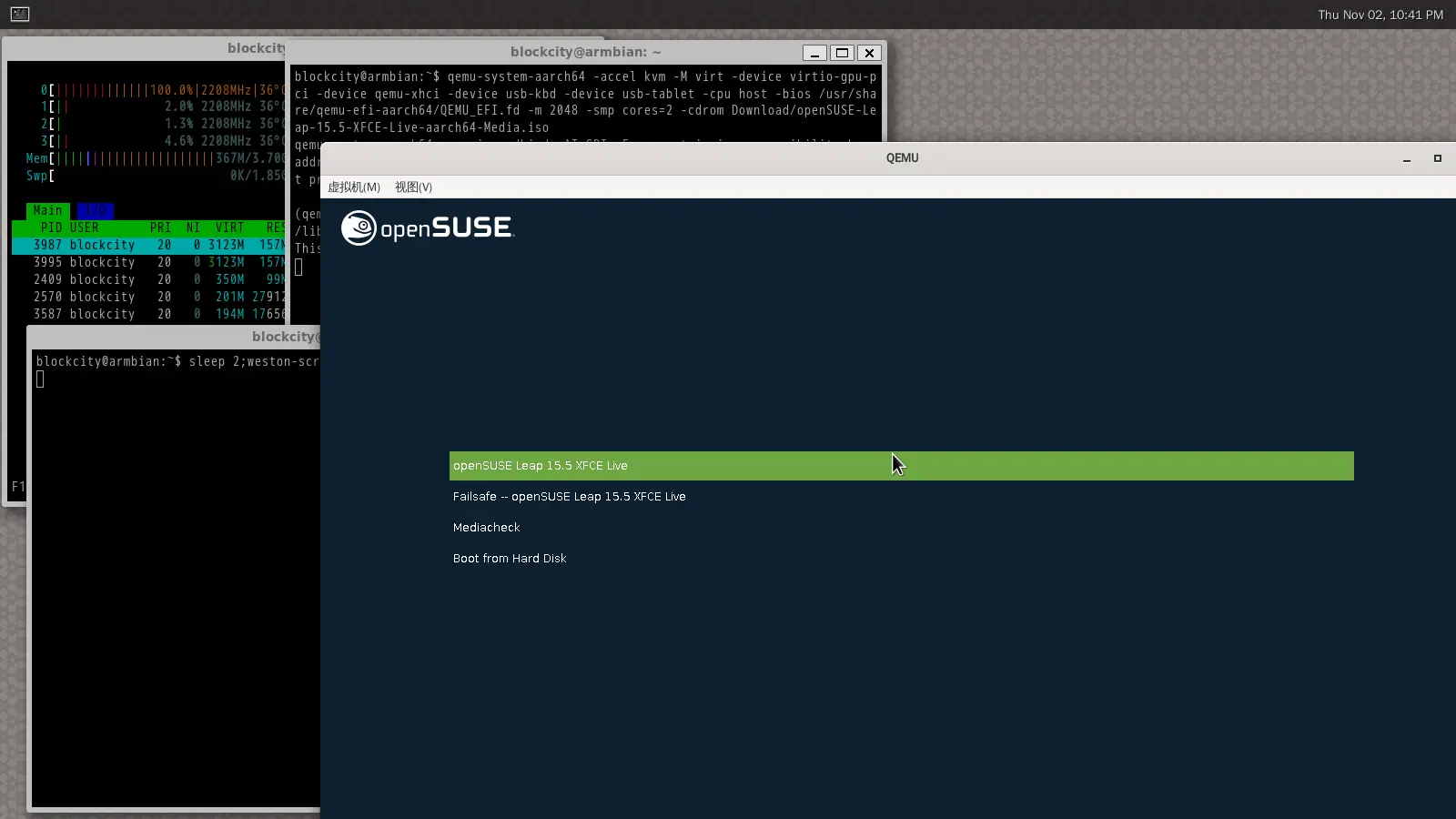
EDK 2 加载 openSUSE LiveCD 就会进 openSUSE LiveCD 上抹茶味道的很漂亮的 GRUB:
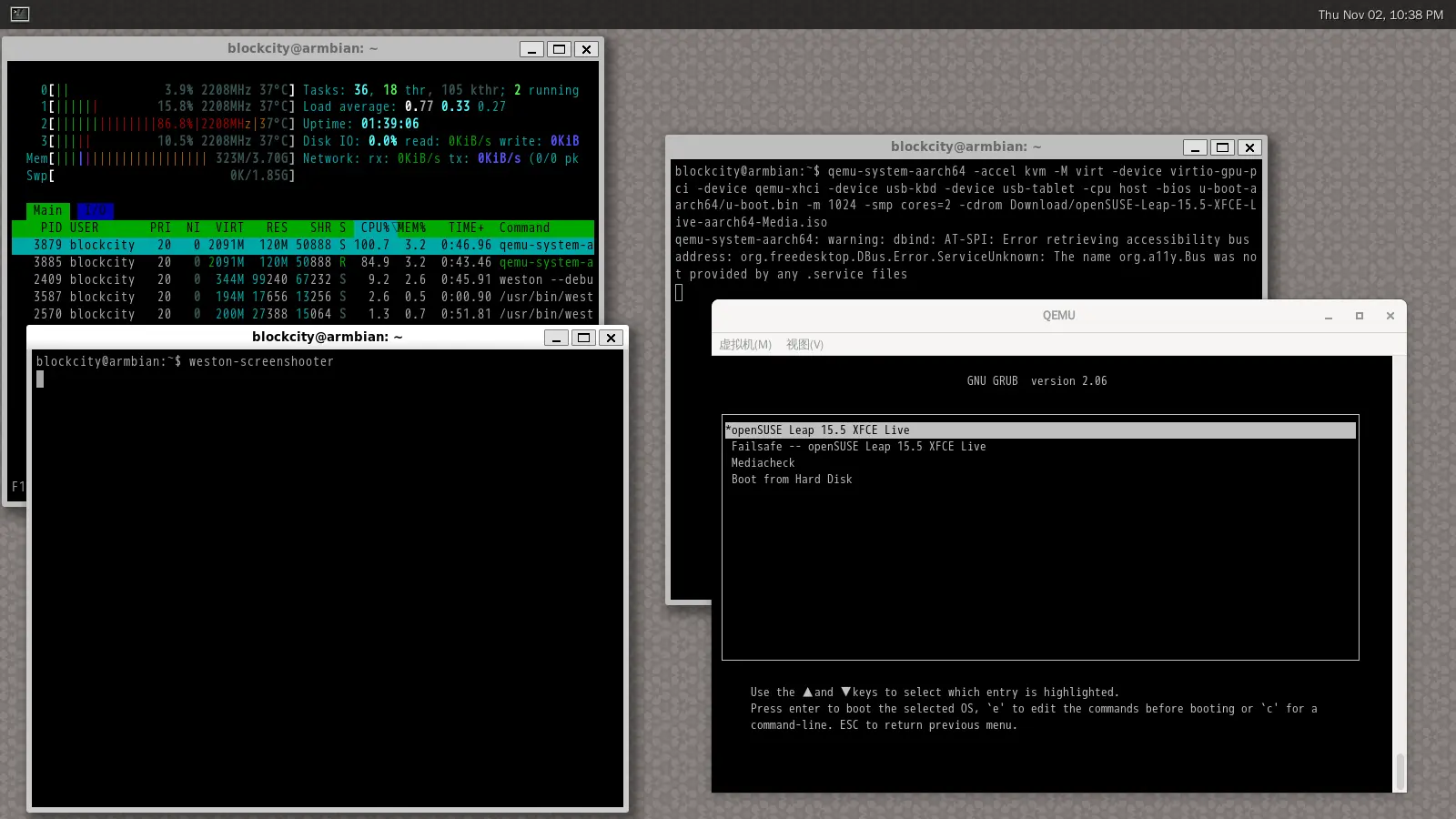
U-boot 加载就要进串行终端操作启动菜单了。
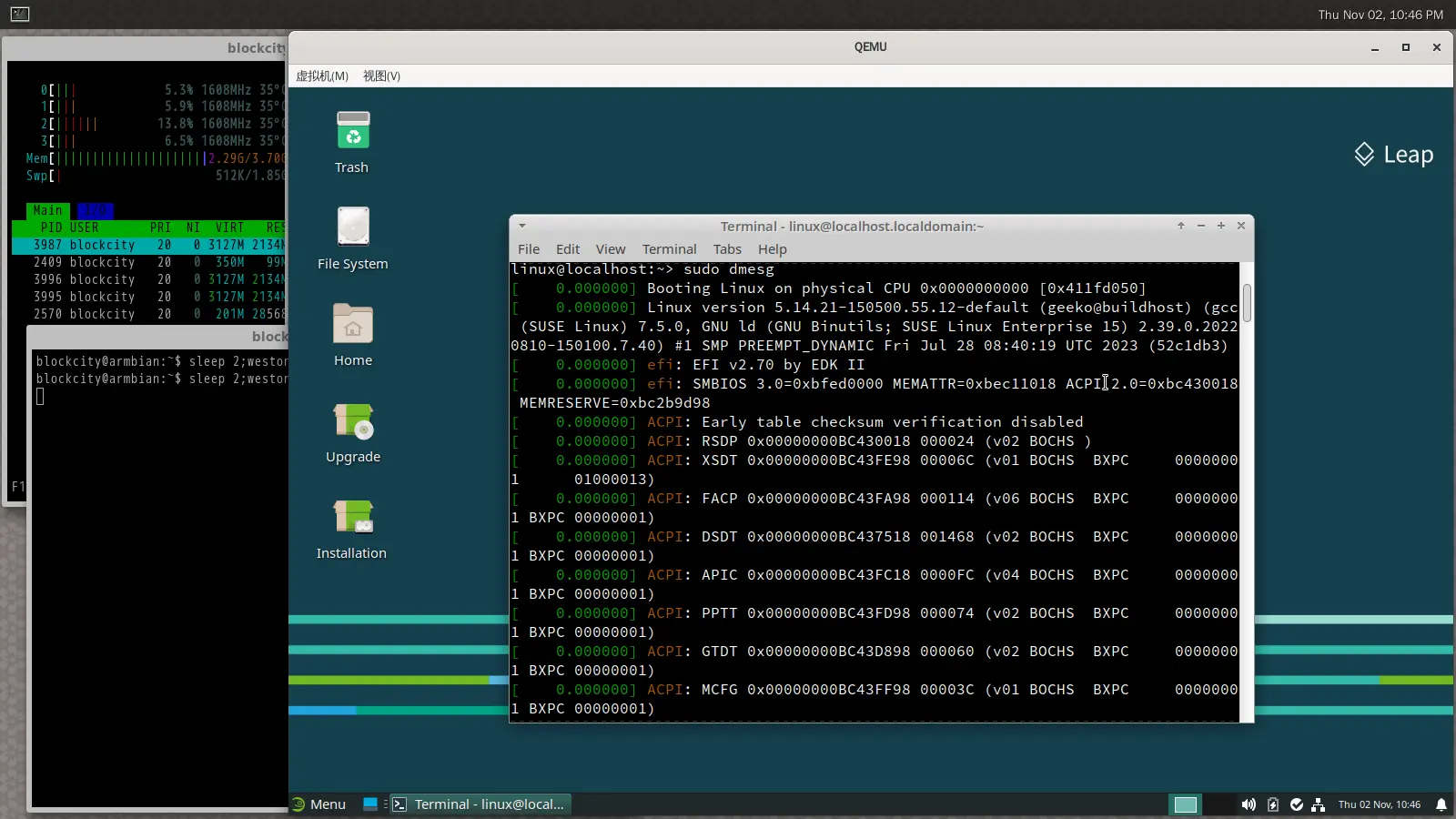
当然这两种都还是 EFI 启动,从 kmsg 里能看到:
你要是恰好有个 Ventoy 盘,也可以试一下从它上面启动(笑)。
有时候 Debian 系发行版要装 qemu-system-x86 才肯安装 VirtIO 相关文件。有种拆包都不会拆的感觉……
话说 ARM 上跑 KVM 干嘛……放 CI 上拿来测试实验品的系统应该很有用吧。不过这是借口,我根本玩不懂 CI。
嵌套虚拟化
没有的不存在的。搜一下 ARM 的嵌套虚拟化,第一页出来的超过一半是论文。
x86 上嵌套虚拟化就显得轻松自如,不知道是什么原理。
TCG
你若是能忍受 QEMU/TCG 的低性能,也可以在普通 x86 PC 上模拟 ARM 设备,只要把 -accel 的 kvm 改成 tcg 就行了,还可以指定个多线程,合起来是 -accel tcg,thread=multi。用 TCG 的话就不能选 -cpu host 了,我一般选 max 或者 cortex-a53。
模拟 RISC-V 也差不多,只是没有很多发行版提供现成的镜像,现成的文档也更少……
Buildroot
Buildroot 是一组给嵌入式设备定制系统的工具,Milk-V Duo 官方只支持用 Buildroot 构建 Linux,其他开发板用了 Buildroot 定制系统也会方便一点,所以学会这个还是很重要的。
简单来说,先获取 Buildroot 工具,之后按文档配置构建选项,之后等着想要的镜像构建出来就可以了。Buildroot menuconfig 下能定制的内核选项很少,实在需要改的话要自己导入改好的配置;选项间常有互斥或者依赖关系,所以很可能要来回翻菜单修改设置;Buildroot 会检查的东西相对较少,检查配置是否正确最好还是自己多看两眼。
改完 Buildroot 配置后有时得做一次完整的编译,要是比较勤劳,一天多编译几次的话硬盘说不定两年就写坏了,我视情况会给 Buildroot output 目录挂载到 tmpfs 上。编译用的机器尽量至少有 16GiB 内存吧。
给 Duo 编译的话,下载 Duo Buildroot SDK,进入 buildroot 目录,选择 Milk-V Duo 的默认配置(make milkv_duo_musl_riscv64_defconfig),按照需要 menuconfig,之后 .config 似乎会被 Duo 的构建脚本覆盖……我直接把 configs/milkv_duo_musl_riscv64_defconfig 用生成的 .config 覆盖了。很暴力,但是确实有效果。
改内核配置的话,回到 SDK 目录,给 build/milkvsetup.sh 的 build_all() 里加上 menuconfig_kernel,启动编译脚本之后等待 menuconfig 界面出现就是了。大概也可以手动选择 .config,但我没找到相关文档。我想用 Bubblewrap,所以在程序炸了几次之后找到并启用了 Control Group support、Namespaces support、Enable signalfd() system call 和 OverlayFS。如果对 cgroup、namespace 相关配置有疑问,可以去看 check-config.sh。
之后发现 lxc-images 里没有 RISC-V 容器镜像,没法偷(不是)现成镜像来用,要自己 bootstrap 一个。确保电脑上正确配置了 qemu-user 和 qemu-binfmt,然后找个干净的目录,debootstrap --arch=riscv64 sid rootfs https://mirrors.tuna.tsinghua.edu.cn/debian。用 Sid 是因为稳定版里还没有 RISC-V 支持。
容器里 APT 不知怎么在连接网络时会有 Illegal Instruction,就传了个 neofetch 包用 dpkg 装了一下。
RVV
感谢 Revy 和 Robin Lu 的指导。
简单玩一下 Duo 上的 RISC-V Vector Extension。关于 RVV 和 x86/ARM SIMD 的区别,这里还不需要过度关注,感兴趣的话可以去读些科普文章。
如果有一组数据需要同时进行同一类型的运算,比如做矩阵乘法的时候(如果还没学线性代数,我比较推荐看一下 Linear Algebra Done Right ),要频繁做两组数据中,一组里的每个数都乘以另一组中一个数的操作,这种情况下用 Vector Extension 相比不用会快一点。
用 RVV 的方法有几种,可以手写汇编,或者用 Intrinsic,也可以让编译器根据程序的语义自动向量化。手写汇编比较恐怖;RVV Intrinsic 是一系列包装好的汇编函数,可以在更高级的语言中安全地使用,用起来就友好一点了。
做计算的时候,要先从内存中取出一些要操作的数,放到向量寄存器里,之后用指令进行算术运算,再从向量寄存器中取出结果,放回内存,重复……
先用 Intrinsic 来个向量加法:
#include <riscv_vector.h>
void rvv_float32_add(const float *a,const float *b,float *ans,size_t length)
{
//先说好,我们把 a+b 写到 ans 里。length 是向量的维数
//不直接把运算结果写回 a 或者 b 里是为了方便检查运算的正确性
size_t vl;//寄存器的空间是十分有限的,我们一次只操作 vl 个元素
vfloat32m1_t va,vb;//设置两个向量寄存器,用来存放一轮操作的几个元素
//元素类型是单精度(32位)浮点数,LMUL 为 1
//LMUL 是指一组向量寄存器的大小,调大 LMUL 可以让几个向量寄存器组成一组,可以少进行几轮循环
for(;length>0;length-=vl)//length 为 0,就说明已经把向量的所有维都算完了
{
vl=vsetvl_e32m1(length);//取得这次要操作多少个元素
va=vle32_v_f32m1(a,vl);//从 a 中加载 vl 个元素,存到 va 里
//可以看出,元素必须是紧挨在一起的
vb=vle32_v_f32m1(b,vl);//从 b 中加载,存到 vb 里
va=vfadd_vv_f32m1(va,vb,vl);//va 与 vb 相加,结果写到 va 里
//即 va[i]=va[i]+vb[i]
vse32_v_f32m1(ans,va,vl);//从 va 中读取运算结果,存到 ans 里
a+=vl;//设置偏移量,为下一轮循环作准备
b+=vl;
ans+=vl;
}
}
之后写个主函数调用这个函数,用 Duo APP SDK 里的工具链编译一下:
path-to-duo-app-sdk/riscv64-linux-musl-x86_64/bin/riscv64-unknown-linux-musl-gcc -o vadd vadd.c -mcpu=c906fdv -march=rv64imafdcv0p7xthead -mcmodel=medany -mabi=lp64d
编译开关是我从 duo-examples 里抄的。编译完 sftp 上传到 Duo,运行一下看看结果。
现在我们已经学会怎么用 RVV 加速向量加法了,再来看一下矩阵乘法。计算矩阵 a × b 的话,得到的结果中第 [i][j] 项就是 a[i][0]*b[0][j] + a[i][1]*b[1][j] + ... + a[i][n]*b[n][j],其中 a[i][0]...a[i][n] 在内存中是连续的,b[0][j]...b[n][j] 彼此之间却要隔一段,不利于我们从内存中取数,所以先给 b 转置一下,记为 bt,原本的表达式就变成了 a[i][0]*bt[j][0] + a[i][1]*bt[j][1] + ... + a[i][n]*bt[j][n]。
先用标量运算实现一个。
void matrix_mtpl(float **a,float **bt,float **ans,int m,int n,int o)
{
//a * b,bt 是 b 的转置。a 是 m*n 矩阵,b 是 n*o
for(int i=0;i<m;i++)
{
for(int j=0;j<o;j++)
{
ans[i][j]=0;
for(int k=0;k<n;k++) ans[i][j]+=a[i][k]*bt[j][k];
}
}
}
之后对着改成用 RVV:
void rvv_matrix_mtpl(float **a,float **bt,float **ans,int m,int n,int o)
{
size_t vl;//和上面的 vl 含义一致
size_t vlmax=vsetvlmax_e32m1();//vl 最大可能的值,相当于下面用到的向量寄存器里,最多存储的元素个数
vfloat32m1_t vzero,vans;
vzero=vfmv_v_f_f32m1(0.0,vlmax);//设置一个全 0.0 填充的向量寄存器,下面有用
for(int i=0;i<m;i++)
{
for(int j=0;j<o;j++)
{
vans=vzero;//vans 存储 a[i][0]*bt[j][0]..a[i][n]*bt[j][n] 的和
//计算开始前将 vans 置零
float *pa=a[i],*pbt=bt[j];//指针指向将要被计算的第一个元素
//初始状态 pa 指向 a[i][0],pbt 指向 bt[j][0]
for(size_t length=n;length>0;length-=vl)
{
vfloat32m1_t va,vb;
vl=vsetvl_e32m1(length);//同样是一次处理 vl 个元素
if(vl<vlmax)
{
va=vzero;//给 va 置零
vb=vzero;
}
va=vle32_v_f32m1(pa,vl);//va 存储 a[i][x],a[i][x+1],...
vb=vle32_v_f32m1(pbt,vl);//vb 存储 bt[j][x],bt[j][x+1],...
//如果 vl < vlmax,剩下的没被设定的部分是 0
//最新 rvv-intrinsic-doc/examples 是没有给 va vb 置零这一步的,可能是因为新版 vfmacc_vv 的行为不太一样
vans=vfmacc_vv_f32m1(vans,va,vb,vlmax);//向量乘加的操作
//此处 va 中的每个元素分别与 vb 中同一下标的元素相乘
//得到的向量再与 vans 相加,即 vans[i]=vans[i]+va[i]*vb[i]
//如果写成 Octave 语法,是 vans=vans+va*vb
//如果vl=4,可以看出 vans[0] 最终会等于 a[i][0]*bt[j][0] + a[i][4]*bt[j][4] + ...
//
//需要说明的是,最新 rvv-intrinsic-doc/examples 里 vfmacc_vv 最后一个参数是 vl(而不是vlmax)
//我这里如果设成 vl,且 vl < vlmax 的话,vans 后一部分的数据(vans[vl,vl+1,...])似乎会丢失
//所以把操作元素数改成了 vlmax。前面的 va vb 置零是为了保证 va,vb 的 [vl,vl+1,...] 是 0
pa+=vl;//设置偏移量
pbt+=vl;
}
vfloat32m1_t vsum;
vsum=vfredusum_vs_f32m1_f32m1(vsum,vans,vzero,vlmax);//求向量vans中各个元素的和(得到标量),
//再与vzero[0](标量,这里是0)相加,写入vsum[0]
//相当于是 vsum[0]=vzero[0]+vans[0]+vans[1]+...
//这就得到 a[i][0]*bt[j][0] + a[i][1]*bt[j][1] + ... 的和
//
//vfredusum_vs 的第一个参数我也不知道是什么意思,实际上好像填什么都不影响运算
//最新 RVV Intrinsic 里是没有第一个参数的
//有些代码在第一个参数处写即将被覆盖的寄存器,所以我也这么写了
ans[i][j]=vfmv_f_s_f32m1_f32(vsum);//取出 vsum[0],写入内存
}
}
}
写完之后还可以比较下用 RVV Intrinsic 与标量运算的耗时,我把实验用的代码放 Github 上了。
Duo 的工具链自动向量化效果不好,NCNN 用的 Intrinsic 版本看样子和 Duo 工具链不兼容,所以都不测了。
写 RVV 0.7.1 的体验不佳,如果有同学想上手但学校不提供免费开发板的话……就再等一两年吧。
题外话
嵌入式确实是坑。算法不是,算法是深渊。这么想的话,“坑”大抵是一种赞美。
玩嵌入式 Linux 和玩 Minecraft 有一点类似,就是不想玩的时候碰都不想碰,但玩上就有点容易上瘾。
计算机行业的发展史,就是一代又一代从业者被淘汰的历史。我现在学的很多东西五年之后全部作废也是完全有可能的吧。
不写了,我要去写线性代数作业了。